
1. 動作環境・対象データ
- デバイスNoとコメントが文字情報を持ったPDF(ベクターデータ)
- Windows PC(10/11)
- Microsoft Excel(出力用)
2. メイン手順
製品版の場合、初回起動時に認証が必要です。
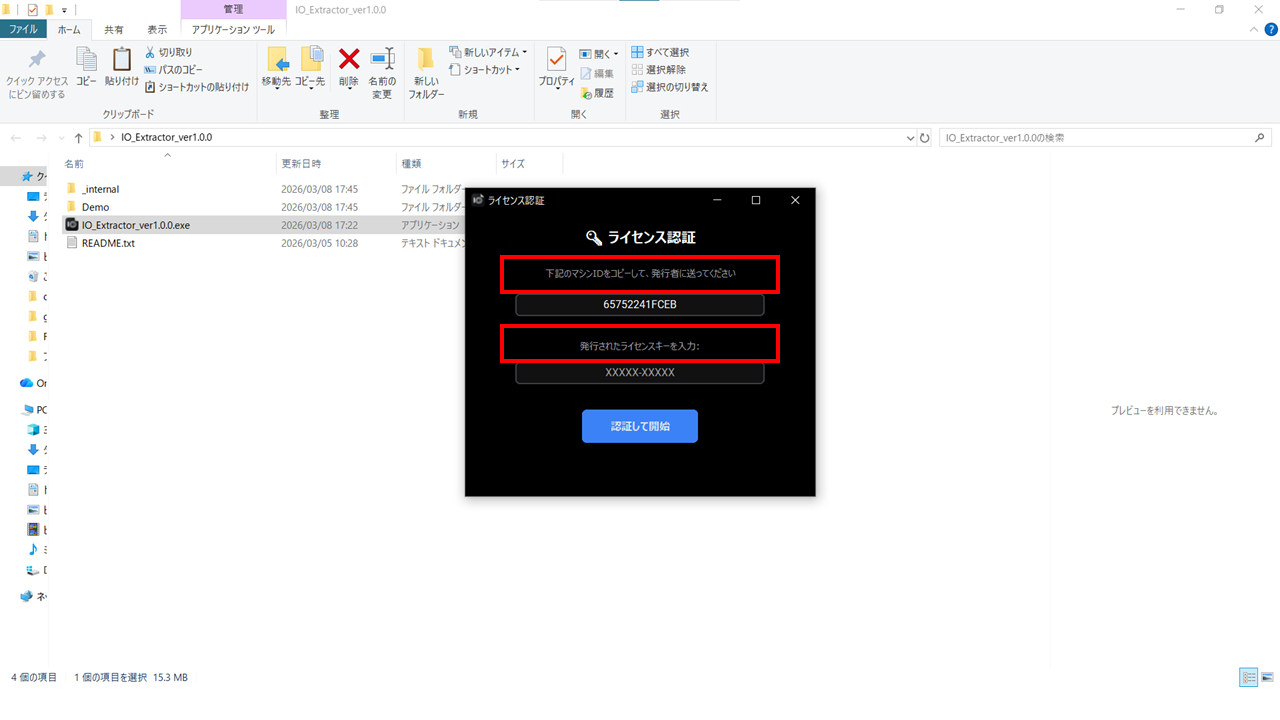
- 手順: ソフト起動後に表示される「マシンID」をコピーし、
info@fa-engi-lab.comへメールで送付してください。 - 完了: 折り返し発行される「ライセンスキー」を入力し、「認証して開始」をクリックしてください。一度認証すれば、同一PC内では継続してご使用いただけます。
- 注意: 実行ファイルと同じ階層にある
_internalフォルダは削除や移動をしないでください。
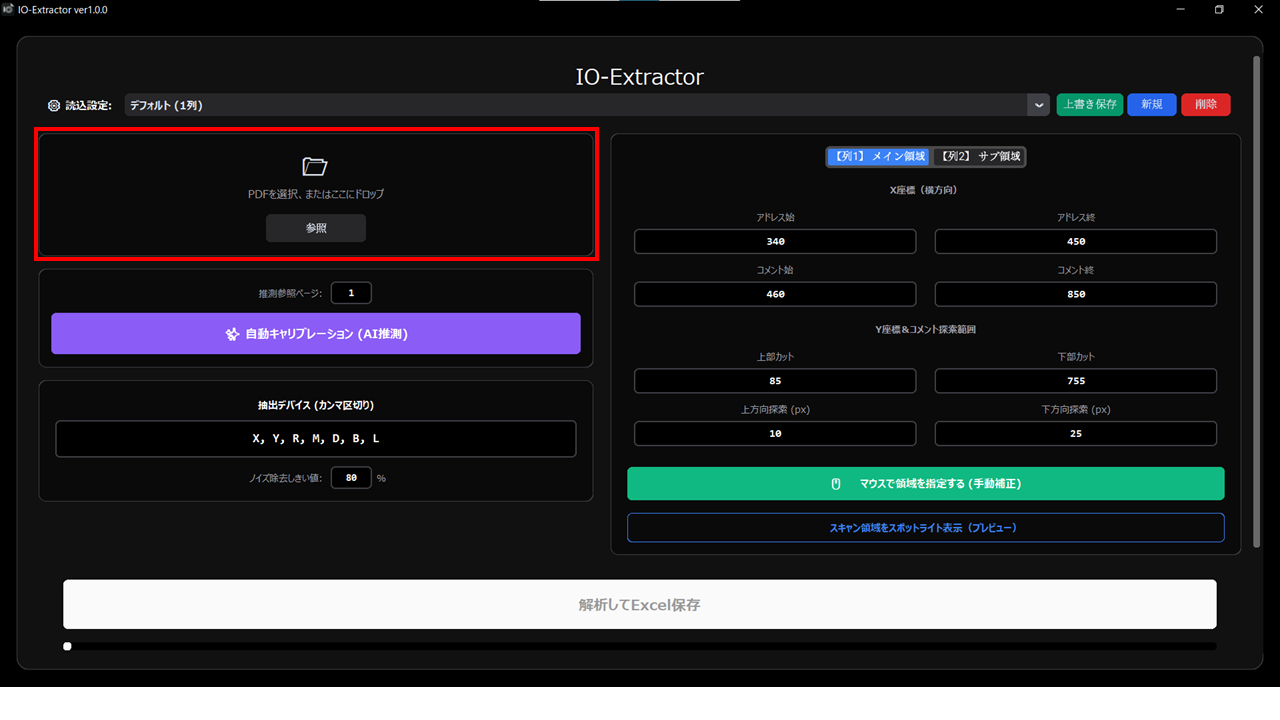
操作: 解析したいPDFファイルをウィンドウ内にドラッグ&ドロップします。
制約: パスワード保護(暗号化)されたPDFは読み込めません。また、文字情報を持たないスキャン画像(ラスタ形式)は解析対象外です。マウスで文字が選択できる「ベクタ形式」のPDFをご用意ください。
「どこに何が書かれているか」の土台をAIが自動で判別します。
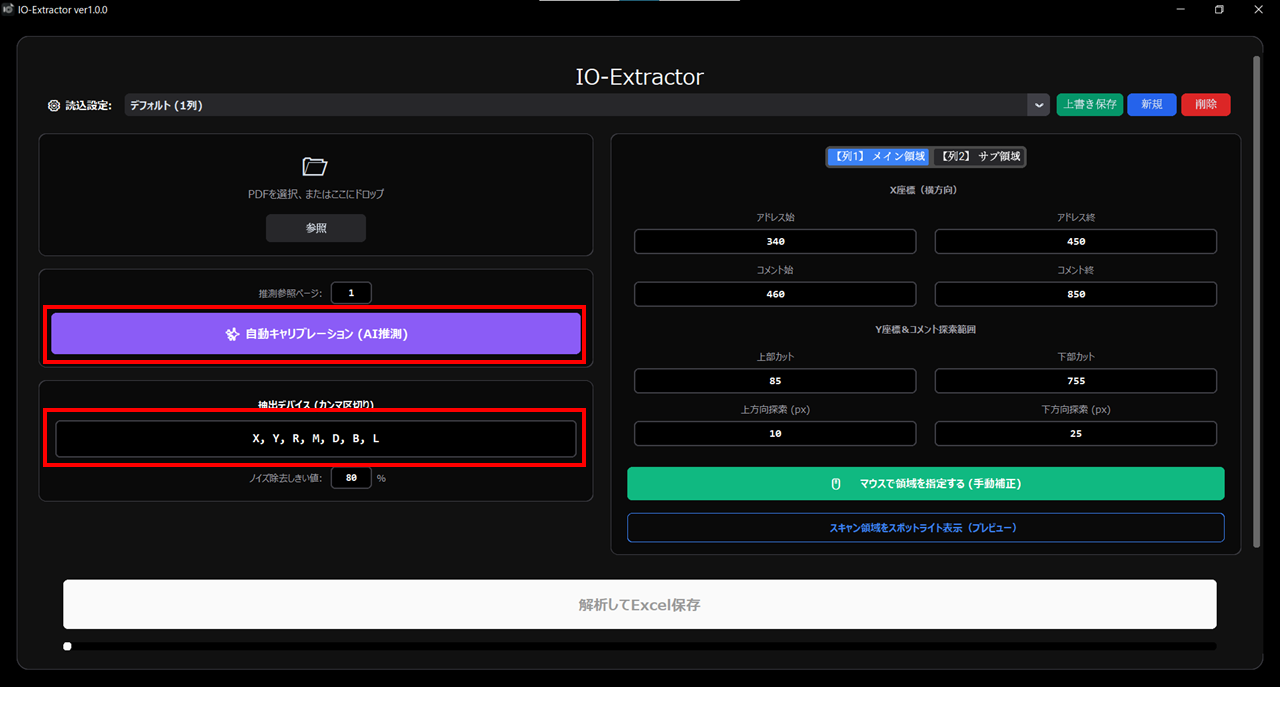
- 手順:
- 抽出したいデバイスの頭文字(例: X, Y)を入力。
- 表が掲載されている「推察参照ページ」を指定。
- 「AI推測」をクリック。
- 自動判別: この操作により、「1ページ内2列構成」かどうかも自動で判別され、チェックボックスが切り替わります。座標数値も自動入力されます。
重要:Step 3のAI推測で自動入力された「暫定の数値」を、この工程で完璧に合わせ込みます。 「数値による設定」と「マウスによる設定」は、全く同じ設定値(座標)を書き換えるための2つの手段であり、どちらの操作も互いの画面に即座に反映(連動)されます。
A. 数値による精密な微調整(座標)
AI推測で自動入力された数値を直接書き換え、文字が枠内に収まるよう調整します。
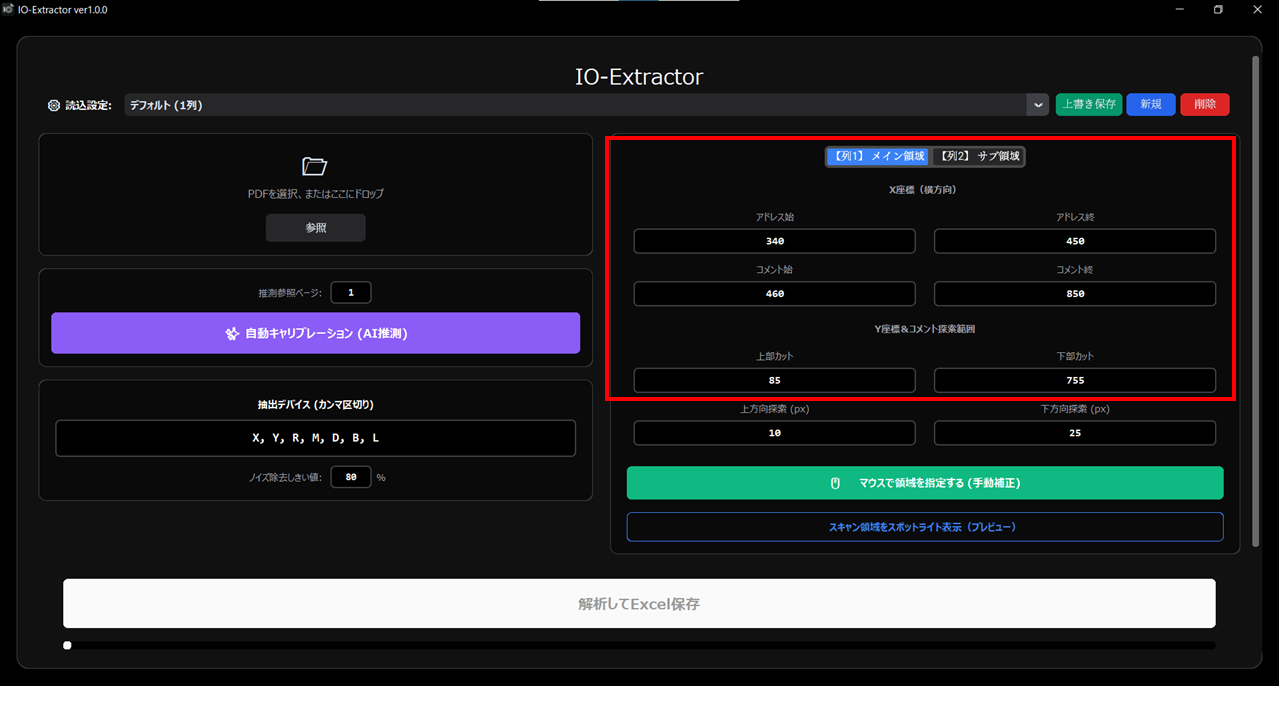
- X軸(横幅の設定):
- アドレス始/終: デバイス名(X0など)を囲む横の範囲。
- コメント始/終: コメント文を囲む横の範囲。
- Y軸(縦方向の設定):
- 上部/下部カット: 図面枠やタイトル欄など、解析から除外したい上下の範囲をピクセル単位で指定します。
- 2列対応:
- 列2をスキャンする: AI推測で自動判別されますが、手動での切り替えも可能です。
B. マウスによる直感的な微調整(座標)
専用画面で視覚的に設定を更新します。ここで変更し「反映して閉じる」を押すと、メイン画面の数値入力欄が自動で書き換わります。
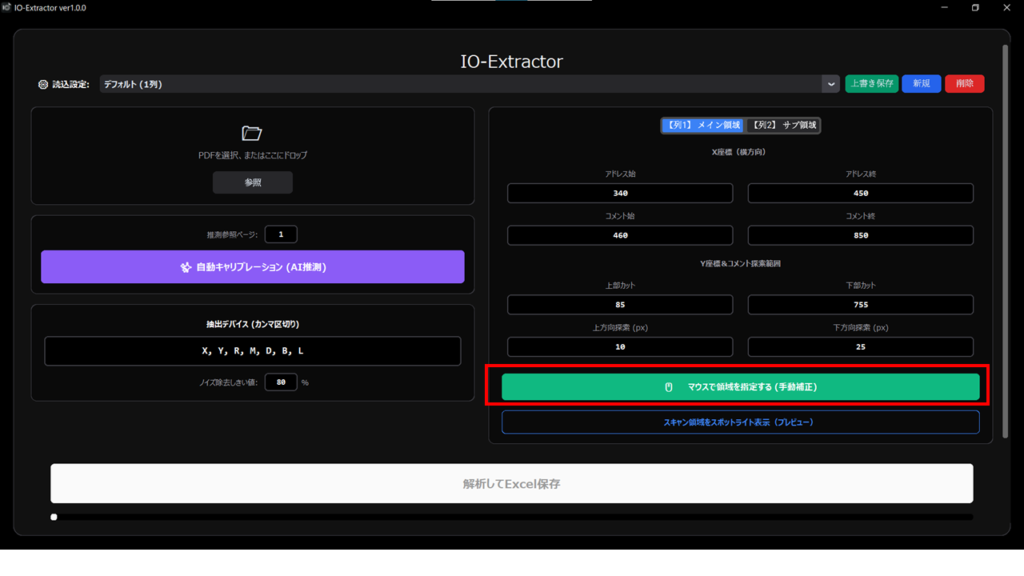
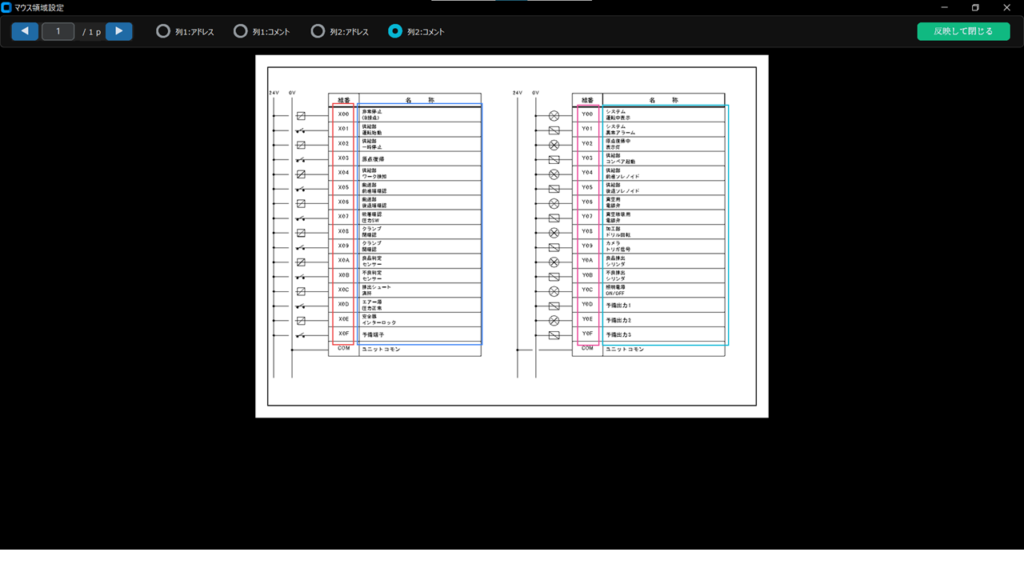
- ドラッグ: 指定した枠の「X座標(幅)」と「Y座標(上下範囲)」を同時に更新します。
- ホイール: 全体の読み取り上限・下限(カット範囲)を**±5pxずつ**微調整します。
C. 文字サイズによるノイズ除去の設定(しきい値)
図面内の小さなゴミや、デバイス名とは無関係な文字を除外するための「フィルタリング強度」を設定します。
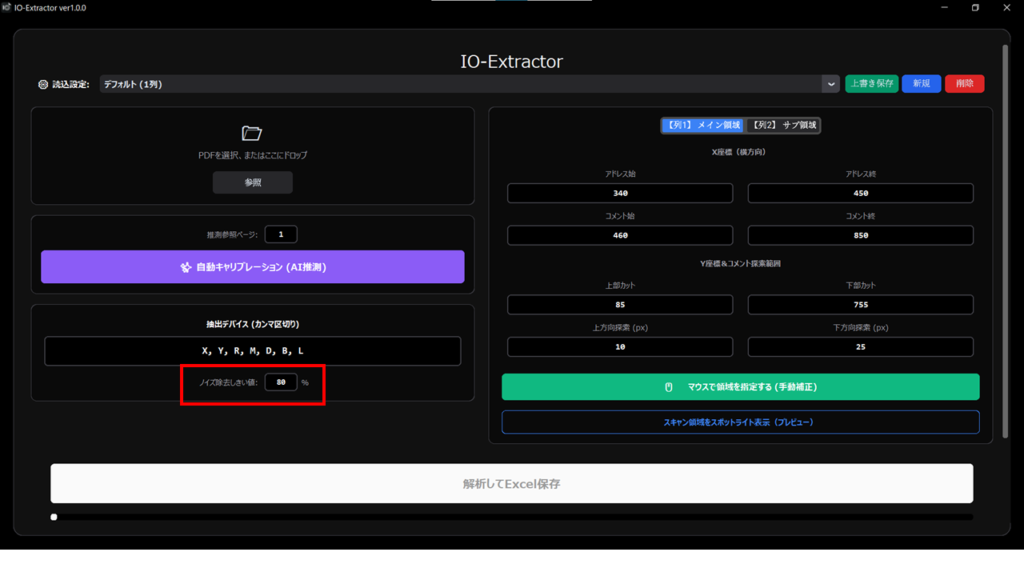
- ノイズ除去しきい値(%):
- 役割: そのページ内で一番大きいデバイス名候補を「100%」としたとき、何%以上の大きさの文字を「本物のデバイス」とみなすかを設定します。
- 目安: 通常は**80%**で問題ありません。小さな注釈などを誤検知してしまう場合は数値を上げ、逆に必要なデバイス名が消えてしまう場合は数値を下げて調整します。
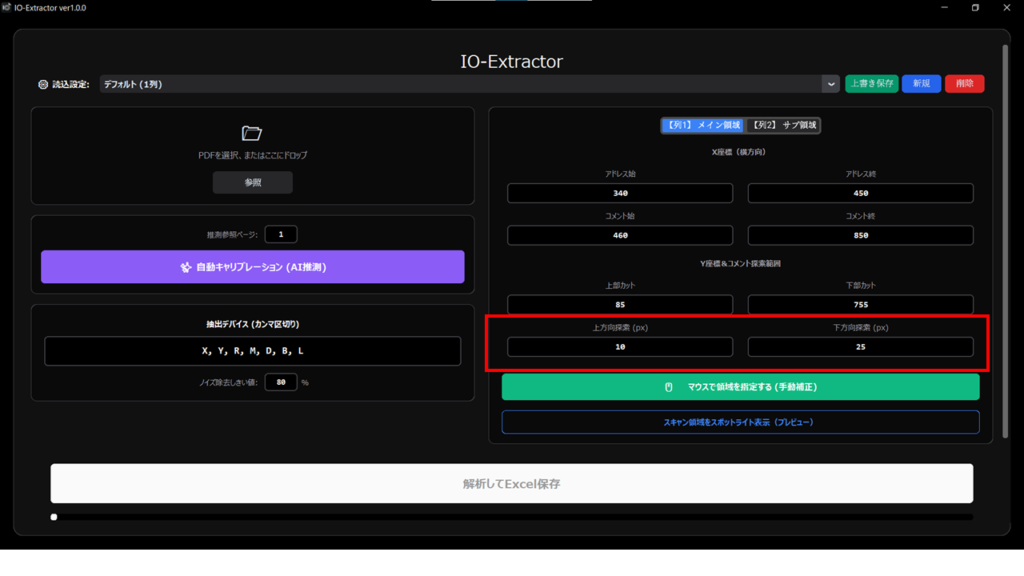
上方向/下方向探索(ピクセル単位): デバイス名に対して、上下何ピクセルの範囲までを「同一のコメント」として結合するかを指定します。
調整のコツ: 広げすぎると隣接する別アドレスのコメントを拾うため、次項の「プレビュー」を見ながら、コメントが途切れず、かつ他を拾わない最適な数値を探ります。
設定した座標やしきい値に基づき、ソフトが「図面のどこを、どう認識しているか」を視覚的にチェックします。
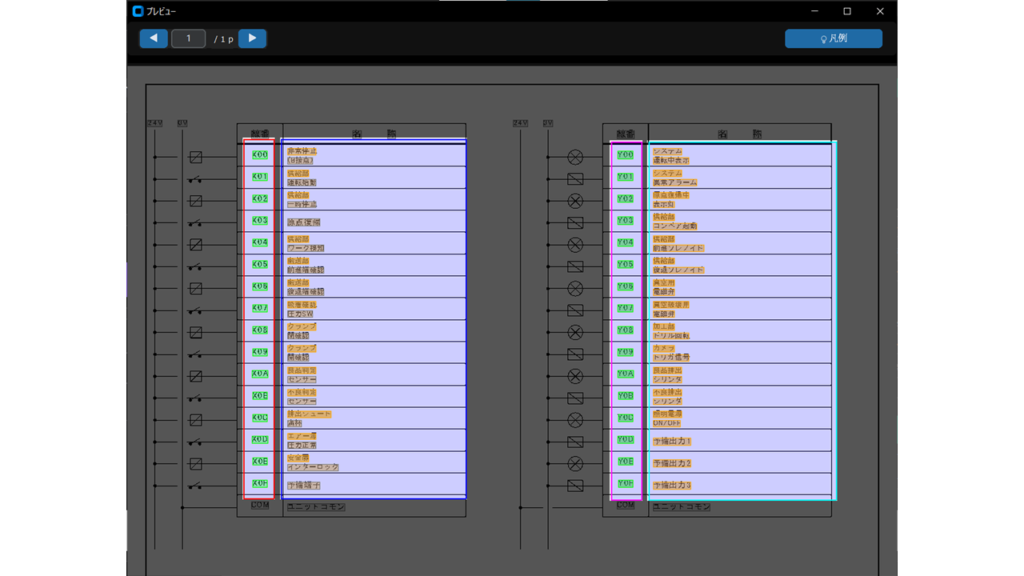
- 操作: メイン画面の「プレビュー表示」をクリック。
- 確認事項1:スポットライトと枠線(解析範囲)
- 解析対象外のエリアは**暗く(グレーアウト)**表示されます。
- 明るく表示されている範囲がスキャン対象です。以下の枠線の中に、文字が収まっているか確認してください。
- 赤枠: 【列1】アドレス(デバイス名)の探索範囲
- 青枠: 【列1】コメントの探索範囲
- ピンク枠: 【列2】アドレスの探索範囲
- 水色枠: 【列2】コメントの探索範囲
- 確認事項2:文字の塗りつぶし(認識状態)
- 枠内の文字には、解析結果に応じて以下の**マーカー(塗りつぶし)**がつきます。
- 緑色: 抽出対象のデバイスとして正しく認識された文字。
- オレンジ色: デバイスに紐づく抽出コメントの内容として認識された文字。
- 灰色: デバイス判定されなかった**「ノイズ(除外)」**。
- 枠内の文字には、解析結果に応じて以下の**マーカー(塗りつぶし)**がつきます。
- 重要:「灰色」の文字について 文字が灰色になっている場合は、以下のいずれかの状態を指します。
- サイズ不足: 「ノイズ除去しきい値」の設定より文字が小さいため、ノイズとして弾かれている。
- 形式の不一致: サイズは十分だが、頭文字(X, Y等)が設定と異なるため、デバイス名として認められていない。
決定した数値を「設定」として保存し、再利用可能にします。
- 操作: 画面上部の「⚙️ 読込設定」から「新規」保存、または既存設定への「上書き保存」を行います。
- 活用: 案件ごとに異なる図面レイアウトの数値を一度保存すれば、次回から瞬時に呼び出し可能です。
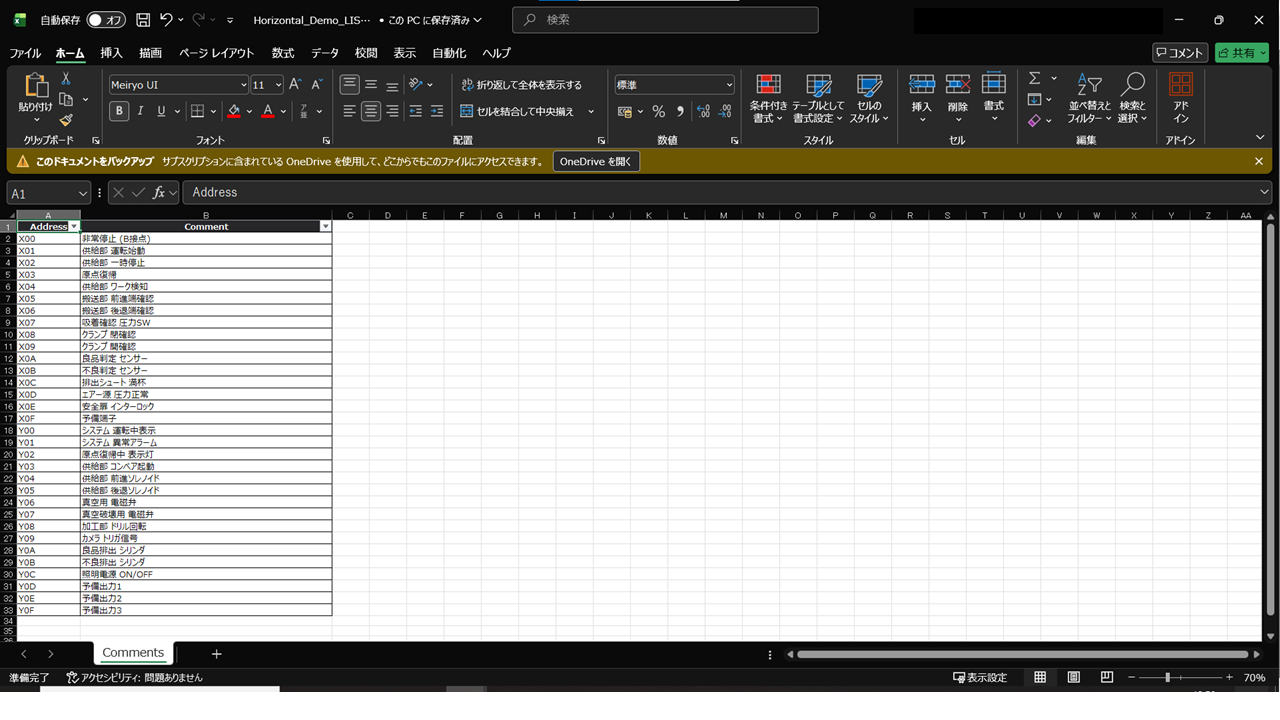
実行: 「解析してExcel保存」をクリック。抽出データがデバイスアドレス順に昇順ソートされ、Excel(.xlsx)として出力されます。
注意: 解析中に同名のExcelファイルを開いていると保存エラーになります。必ずファイルを閉じてから実行してください。
3. 困ったときは
[Q] 起動時にWindowsの保護画面(青色)が表示される
[A] 「詳細情報」→「実行」を選択してください(初回のみ)。
[Q] 文字が全く抽出されない / プレビューに光が出ない
[A] 解析対象のデバイスNoとコメントがベクターデータかどうか確認してください。
ベクターデータでない場合は解析できません。
[Q] 抽出したい文字がプレビューで灰色になっている
[A] 文字サイズが小さすぎて「ノイズ」判定されている可能性があります。Step 4-Cの「ノイズ除去しきい値」を下げて調整してください。